This is the first of a three-parter where I will go over and annotate the code for Dragonflow’s publish/subscribe mechanism. In this first part, I will review the API. Part 2 will give API usage examples, and Part 3 will give driver implementation examples.
Introduction
As part of the Dragonflow architecture, Dragonflow uses a NoSQL database for storage. This database stores elements such as port, switch, routers and their interfaces.
The information stored in the database needs to be propagated to all compute nodes. Obviously, this can be done by polling, but this is very inefficient.
Alternatively, this can be done using a publish-subscribe mechanism. Updates can be published from the controllers, and the compute nodes are subscribers. The upshot is that some databases, e.g. etcd, redis, have a built-in publish/subscribe mechanism.
The down-shot is that some databases do not.
To mitigate this problem, Dragonflow has its own publish/subscribe mechanism, implemented independantly of the database. A deployment can either use the database’s publish/subscribe mechanism, or Dragonflow’s.
A deployment can also use both, by using the database’s publish/subscribe driver.
In this part, I will show the publish/subscribe API. When publish/subscribe mechanism are to be used, a driver for them must be developed (by a driver developer). That driver will have to implemenet the API methods presented here. Two driver examples will be presented in Part 3.
High Level Design
In our specific case, the players are:
-
- Controller Nodes (Running Neutron Service, with Dragonflow plugin)
- The configuration is set on these servers. They write the information to the database. They also publish the information to the compute nodes.
-
- Compute Nodes (Running Dragonflow Controller)
- The configuration is implemented here. Dragonflow verifies that VMs on specified virtual L2 and L3 networks behave as expected.
-
- Database Nodes (Running e.g. etcd, redis)
- The configuration is stored here. Technically, Neutron has its own datanase, but that is irrelevant to our discussion.
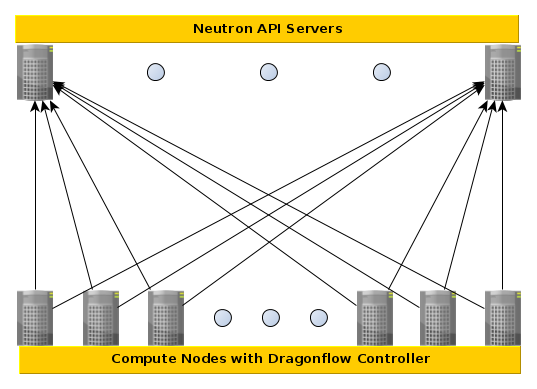
(Note: This image was taken from the Dragonflow documentation)
When there is a configuration change on one of the Controller Nodes, the change is written to the database on the Database Nodes, and published to the Compute Nodes. The publishing process (this posts’ main subject) can be done automatically by some database implementations. However, not always very well.
Multi process publisher
There is a small detail that I ignored so far: The services on the Neutron Controller are forked per core. This means that there is a Neutron Service Process for every CPU core on the system.
This means that if the Dragonflow pub/sub service wants to bind to a specific port, especially in TCP, it can’t.
To overcome this, we added a publisher service, which runs once on the Controller Node, and binds the port. All publishers from within the Neutron Service connect to it, and it publishes the information to the Compute Nodes.
I will sometimes call the communication process between the publisher service and the Neutron service processes an inter-process publish/subscribe mechanism.
The communication between the controller and the compute nodes will be called here cross-node publish/subscribe.
Broker Based Pub/Sub
As opposed to multi-process publishers, there is also a broker-based publisher mechanism. In this mechanism, there is an external entity (the broker), to which publishers and subscribers connect. The publishers send events to the broker, which passes these events around to the subscribers.
In some cases, the broker can even be distributed, thus making sure it does not become a single point of failure.
API
Now we get to dirty our hands with some code. I’ll be looking at commit b325a3a. Note that Dragonflow is an open-source project still in progress, meaning that new commits are added regularly. Therefore, some information here may be out-of-date even before I finish writing this post. In other words, bear with me.
The implementation calls for a publisher class, a subscriber class, and a manager class. The manager returns the publisher and subscriber.
Publisher
The publisher class is simple - you only need to be able to send events. The original code of the class is available here, with its documentation.
class PublisherApi(object):
def initialize(self):
"""..."""
def send_event(self, update, topic):
"""..."""
The initialize method initialises the publisher. The following tasks are
handled within:
-
Read initial configuration.
-
Bind and listens on the port.
-
Connect to the broker.
Not everything is necessary. e.g. if the publishing mechanism uses a broker, it does not have to bind and listen to a port.
The send_event method actually sends a message (surprise!). update is an
instance of DBUpdate, which I will show shortly.
The topic parameter allows overriding the channel. In general, Pub/Sub
mechanisms allow subscribers to filter according to channel, or topic. Whilst
DBUpdate contains a topic field, the topic parameter allows the caller to
override it.
I will use channel and topic interchangibly, occasionally writing both, just to annoy the critics.
DBUpdate
The DBUpdate class is the event sent by the publisher to the subscribers. It
can be found here:
class DbUpdate(object):
"""Encapsulates a DB update
An instance of this object carries the information necessary to prioritize
and process a request to update a DB entry.
Lower value is higher priority !
"""
def __init__(self, table, key, action, value, priority=5,
timestamp=None, topic=SEND_ALL_TOPIC):
self.priority = priority
self.timestamp = timestamp
if not timestamp:
self.timestamp = timeutils.utcnow()
self.key = key
self.action = action
self.table = table
self.value = value
self.topic = topic
def to_dict(self):
update = {
'table': self.table,
'key': self.key,
'action': self.action,
'value': self.value,
'topic': self.topic
}
return update
def __str__(self):
return "Action:%s, Table:%s, Key:%s Value:%s Topic:%s" % (
self.action,
self.table,
self.key,
self.value,
self.topic,
)
def __lt__(self, other):
"""Implements priority among updates
Lower numerical priority always gets precedence. When comparing two
updates of the same priority then the one with the earlier timestamp
gets procedence. In the unlikely event that the timestamps are also
equal it falls back to a simple comparison of ids meaning the
precedence is essentially random.
"""
if self.priority != other.priority:
return self.priority < other.priority
if self.timestamp != other.timestamp:
return self.timestamp < other.timestamp
return self.key < other.key
The DBUpdate class is a container for the following fields:
-
action- The performed action. Usually
create,set, ordelete. However, other options exist such aslog(Have the subscriber write to its log) orsync(Have the subscriber re-sync its database).
-
table- The table on which the action is performed, e.g. lrouter, lport, lswitch.
-
key- The key of the added, modified, or deleted row.
-
value- The new value of the row. Note that at the time of writing, value was
always set to
Nonein the ZMQ driver. This will be seen in Part 3.
-
topic- The channel on which the message is sent.
It also contains other important information, such as timestamp and
priority, which is used to decide which event is handled first. It can be
seen in the __lt__ method that updates are priorotised first by their
priority, then by their timestamp, and then by their keys.
Subscriber
The subscriber API is also available here.
A watered down version looks like this:
class SubscriberApi(object):
def initialize(self, callback):
"""..."""
def register_listen_address(self, uri):
"""..."""
def unregister_listen_address(self, uri):
"""..."""
def run(self):
"""..."""
def daemonize(self):
"""..."""
def stop(self):
"""..."""
def register_topic(self, topic):
"""..."""
def unregister_topic(self, topic):
"""..."""
The subscriber is responsible for connecting to the publishers (or broker), registering to channels (or topics), and listening for events. It is written as a separate thread, so as not to block the main thread.
The initialize method here is very similar to the publisher’s initialize
method. It is responsible to connect to the publishers or the broker. It can
also read initial configuration, and set up pre-defined URIs and topics. The
callback parameter is a callable, to be called when a published event
arrives.
register_listen_address and unregister_listen_address allow the caller to
add and remove new publishers. In broker based Pub/Sub, the implementation may
use these methods to add and remove brokers (but it doesn’t have to).
register_topic and unregister_topic allow the caller to add and remove new
channels. This will prove handy in selective event distribution, where the
Pub/Sub method will only receive events relevant to the tenants already
installed (in this case the topic is the tenant’s ID).
run is the main listening loop. Its task is to continuously wait for events
from the publisher. Note that since Dragonflow uses greenthreads (cooperative
threading), it is important that the method used to wait for events
relinquishes the CPU. Once an event is received, it is passed to the callback
method that was passed as an argument to initialize.
daemonize starts a new thread, and calls the method run. stop shuts
the thread down.
Manager
A Pub/Sub driver needs to implement a manager. The manager returns publisher and subscriber instances.
class PubSubApi(object):
"""..."""
def get_publisher(self):
"""..."""
def get_subscriber(self):
"""..."""
The original code is available here.
The manager’s constructor takes no arguments, and returns (when asked nicely) an instance of the publisher, and an instance of the subscriber.
In case of multi-process Pub/Sub, this interface is implemented twice: Once for cross-node publish/subscribe, and once for inter-process (multiproc) publish/subscribe.
In the case of the publisher service, the subscriber is in fact an IPC subscriber - It receives events from the Neutron plugin publisher, and then publishes them to the subscribers on the compute nodes.
In the case of the Neutron plugin, the publisher uses the same IPC method to pass the information to the subscriber in the publisher service.
In ZMQ, for instance, this is in fact a PUSH/PULL mechanism, since there is one subscriber, and many publishers (whereas Pub/Sub has in general one publisher, and many subscribers).
Base Classes
In addition to the base API, Dragonflow also provides a base class for the Subscriber API, to help the implementation of new drivers.
Subscriber
The subscriber abstract class (SubscriberAgentBase, also available here)
provides support for storing the callback, implementing the threading part of
the code, and helps with the bookeeping of URIs and topics.
Since there is finally real code here, I’ll do this one in bite-sized bits.
class SubscriberAgentBase(SubscriberApi):
def __init__(self):
super(SubscriberAgentBase, self).__init__()
self.topic_list = []
self.uri_list = []
self.topic_list.append(db_common.SEND_ALL_TOPIC)
The constructor sets up the lists that will hold the topics and URIs. It also registers the general topic. (This part is moved to the caller in a later commit).
def initialize(self, callback):
self.db_changes_callback = callback
self.daemon = df_utils.DFDaemon()
Store the given callback, since the implementation will need it later.
Create a DFDaemon instance. This is a helper class to create threads (Similar
to threading.Thread). The decision not to use mixins here was to avoid multiple
inheritance, which we find less readable.
def register_listen_address(self, uri):
self.uri_list.append(uri)
def unregister_listen_address(self, topic):
self.uri_list.remove(topic)
Add and remove the URI from the URI list. The driver developer is expected to
extend these methods to also connect and disconnect from these addresses once
initialize was called.
def daemonize(self):
self.daemon.daemonize(self.run)
@property
def is_daemonize(self):
return self.daemon.is_daemonize
def stop(self):
self.daemon.stop()
These methods wrap the DFDaemon methods to start and stop the subscriber’s
thread. is_daemonize allows the caller to test if the subscriber’s thread was
already started.
def register_topic(self, topic):
LOG.info(_LI('Register topic %s'), topic)
topic = topic.encode('ascii', 'ignore')
if topic not in self.topic_list:
self.topic_list.append(topic)
def unregister_topic(self, topic):
LOG.info(_LI('Unregister topic %s'), topic)
topic = topic.encode('ascii', 'ignore')
self.topic_list.remove(topic)
Register and unregister a topic. Here as well, the driver is expected to extend these methods to register to or unregister from these channels. This is not mandatory, and some drivers may simply filter events by checking if the topic is in topic list, e.g.
def _is_filter_topic(self, update):
""" Test if the update is to be filtered in. Note: Untested code """
return (update.topic in self.topic_list)
Conclusion
So far, we have seen the API of Dragonflow’s publish/subscribe mechanism.
In the next part, I will go over some of the code in Dragonflow which connects with this API.
In the third part, I will go over and annotate two publish/subscribe driver implementations.